9.3k
GitHub Stars
6M+
Downloads
300+
Enterprise Users
$10M
Savings

















Australian owned, trusted globally
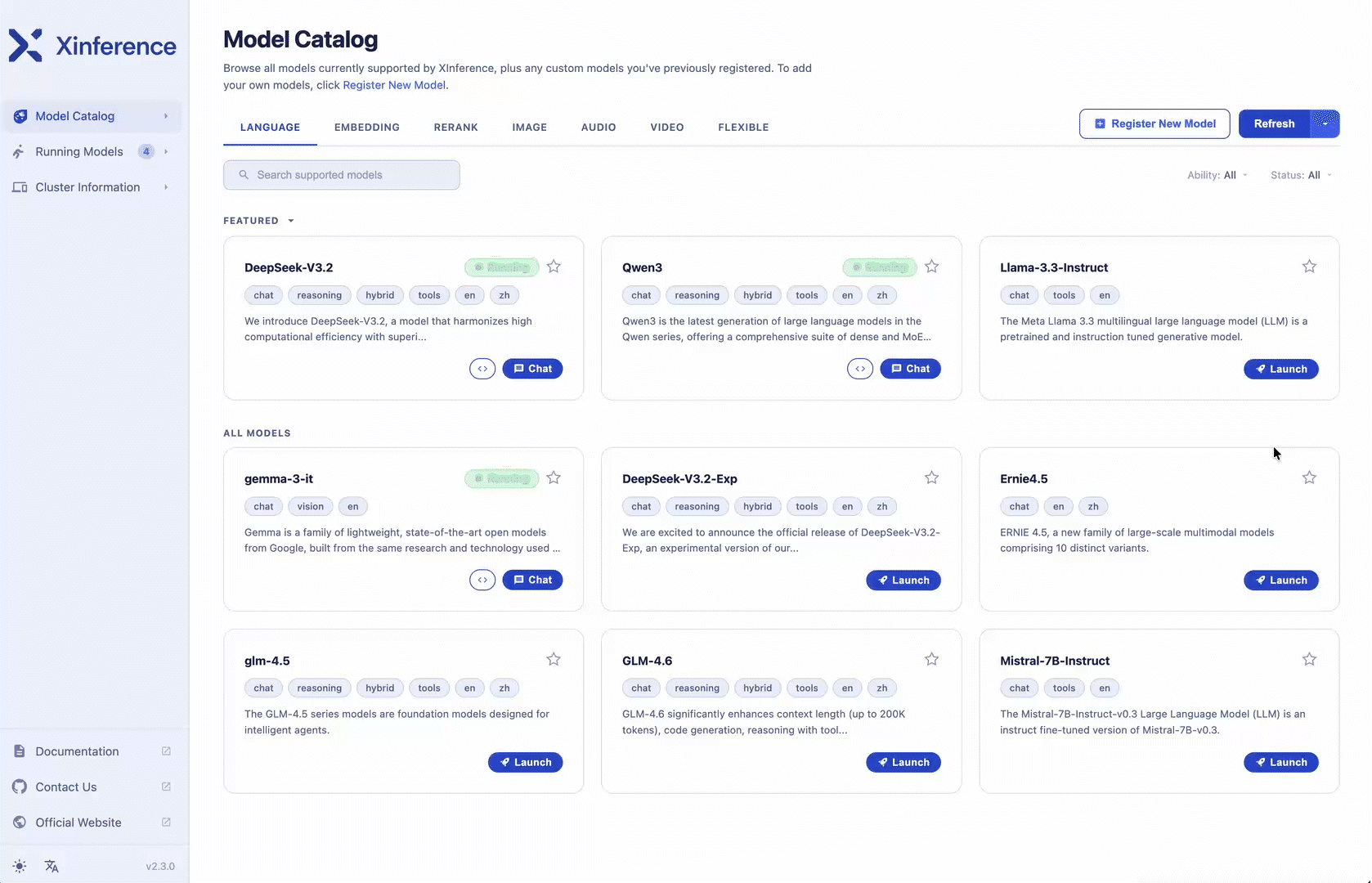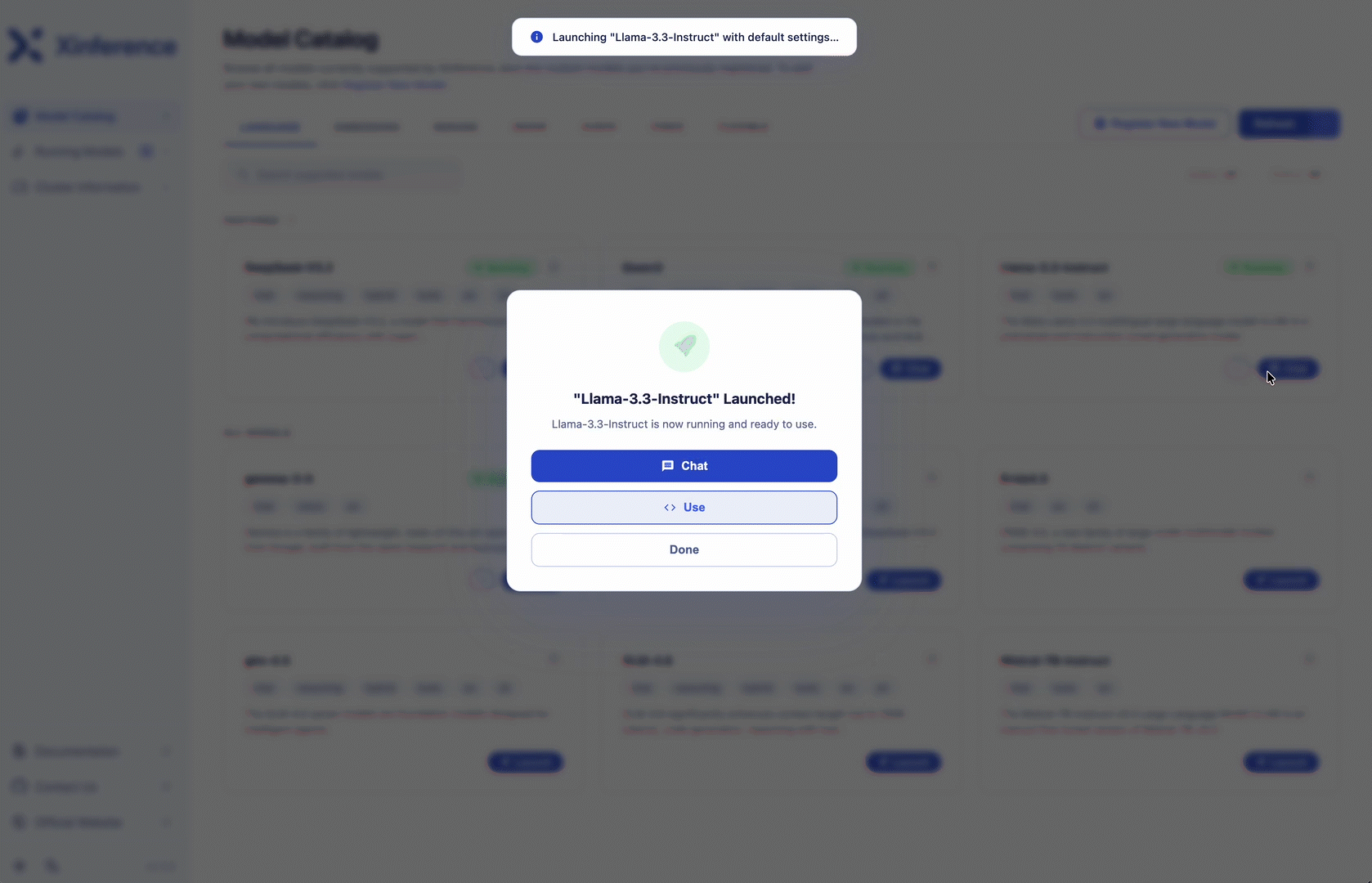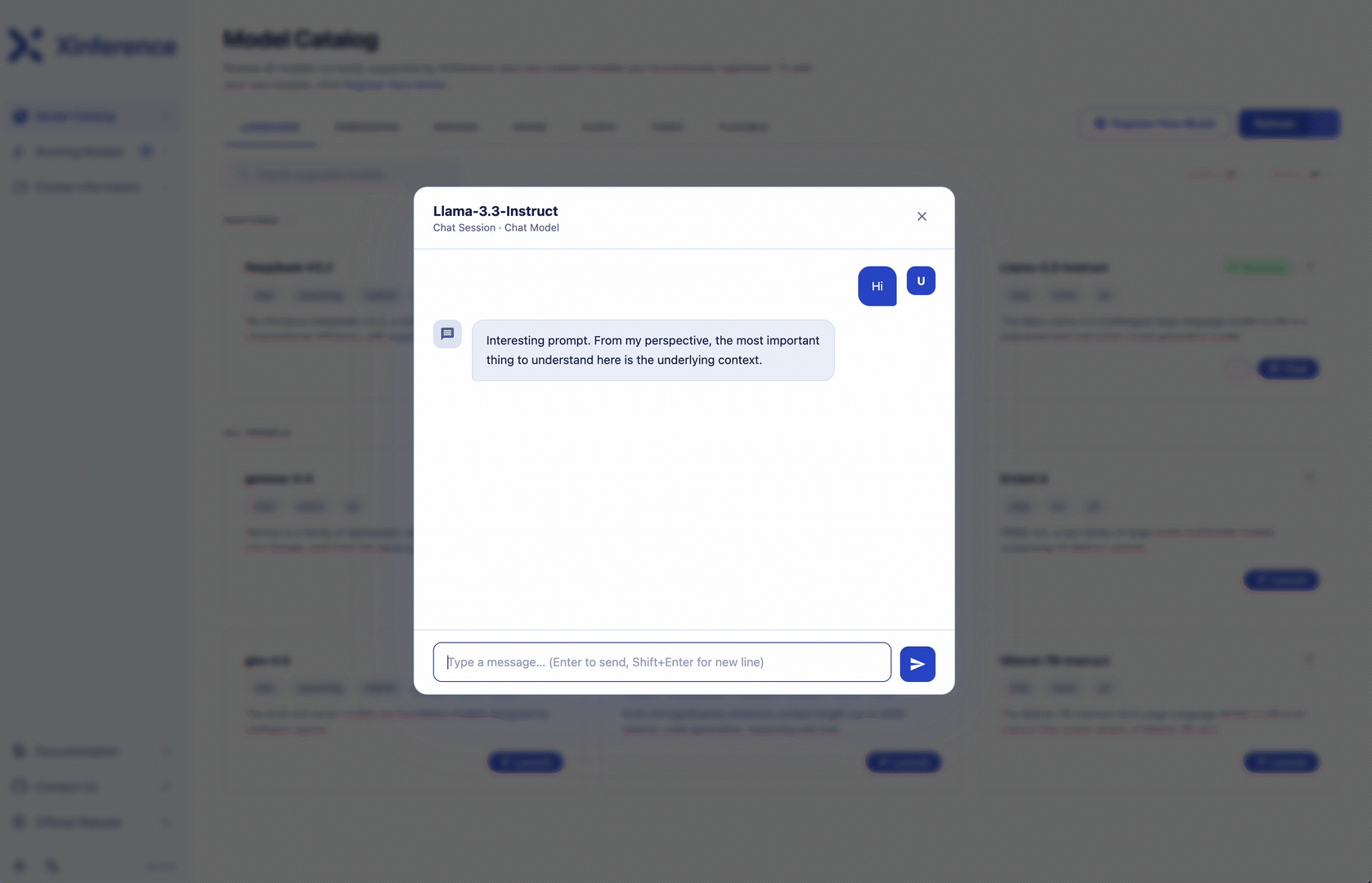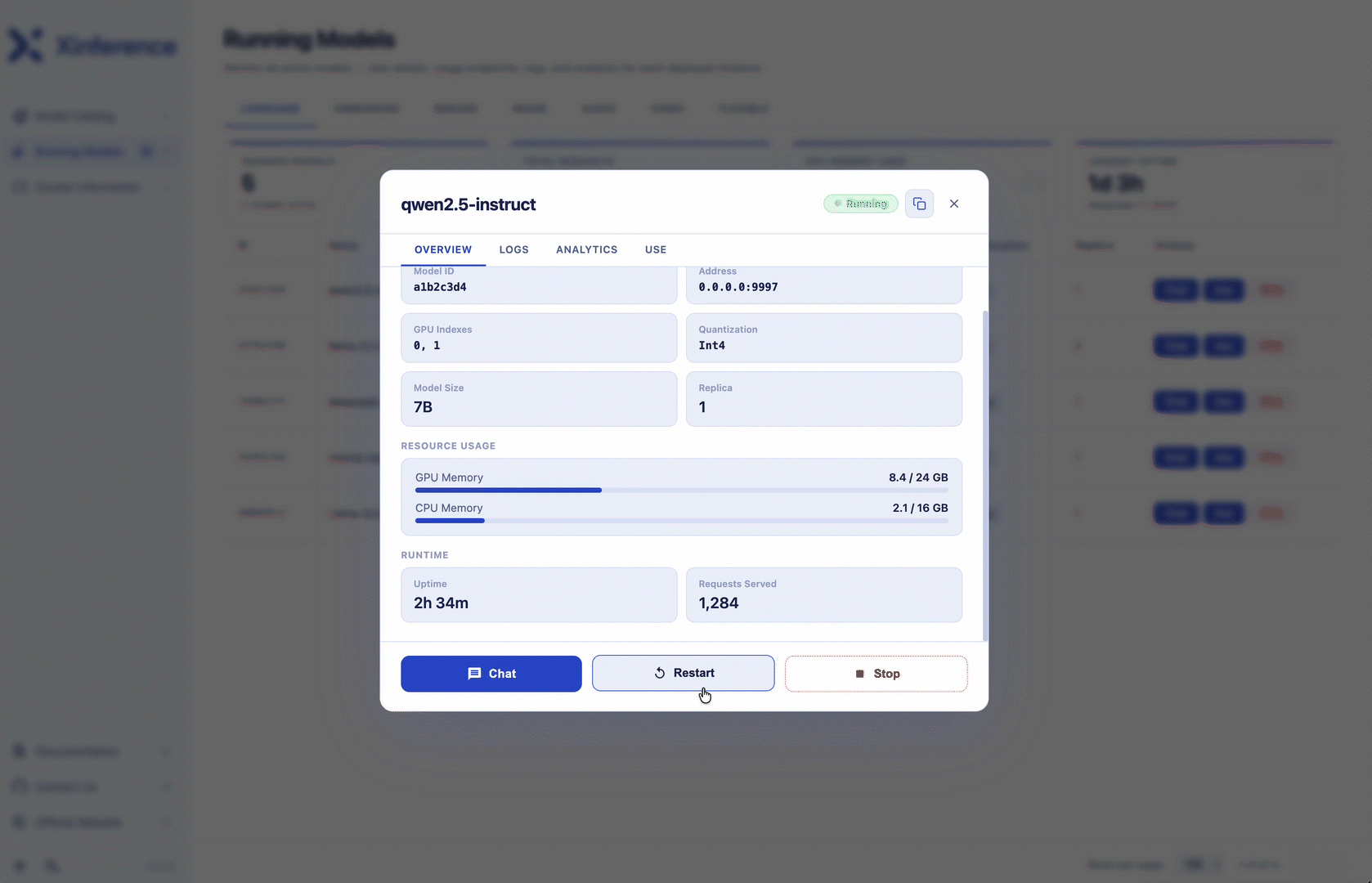
 Gemini
Gemini
 Claude
Claude
 NVIDIA
NVIDIA
 AMD
AMD
 Intel
Intel
 Meta
Meta
 HuggingFace
HuggingFace